简介
kubelet 组件作为每台 kubernetes 集群中每台计算节点上运行的 agent,主要职责有两个
- 管理这台机器上面的 pod 的生命周期,
- 自动上报,并且维护这台计算节点的状态
这篇文章的目的就在于对 kubelet 整体的设计框架进行分析。并不会对任意一个子功能的细节进行深入的介绍。后续会有一系列文章对 kubelet 组件的各种功能进行详细的介绍。
kubelet 内部结构
kubelet 内部其实是由多个【子模块】来构成的,每个子模块都单独负责一部分的任务,而在代码中,所有的子模块对象都包含在下面两个对象中,这两个对象也是 kubelet 中最重要的两个对象
kubeDeps:该对象(类型为 Dependencies)主要包含一些 kubelet 依赖的外部功能,比如 cadvisor(监控功能),containerManager(cgroup 管理功能)。
kubelet:kubelet 对象(类型为 Kubelet)则代表 kubelet 内部跟 pod 息息相关的子模块,比如 podManager(pod 信息存储模块),probeManager(pod 测活模块)等等。
那么 kubelet 中各个子模块之间又是如何配合工作的呢?主要是基于生产者消费者的模型。
整个 kubelet 的工作模式就是在围绕着不同的生产者生产出来的不同的有关 pod 的消息来调用相应的消费者(不同的子模块)完成不同的行为,比如创建 pod,删除 pod,如下图所示
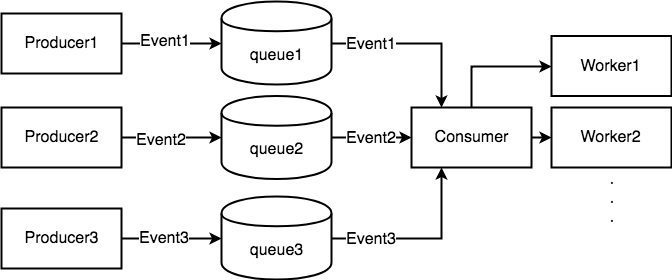
那么 kubelet 中主要包含哪几个消息的生产者呢?消费者又是怎么消费的呢?
我们可以在 kubelet 的 syncLoopIteration 函数中看到 kubelet 到底同时接收哪几个信息源
|
|
通过代码注释可以看出,kubelet 主要有 5 个不同的信息源
- configCh: 该信息源由 kubeDeps 对象中的 PodConfig 子模块提供,该模块将同时 watch 3 个不同来源的 pod 信息的变化(file,http,apiserver),一旦某个来源的 pod 信息发生了更新(创建/更新/删除),这个 channel 中就会出现被更新的 pod 信息和更新的具体操作。
- plegCh: 该信息源由 kubelet 对象中的 pleg 子模块提供,该模块主要用于周期性地向 container runtime 查询当前所有容器的状态,如果状态发生变化,则这个 channel 产生事件。[1]
- syncCh: 该信息源是一个周期性的信号源(默认1秒),周期性同步所有需要再次同步的 pod。
- liveness manager update: 该信息源是由 kubelet 对象中 livenessManager管理,当某个容器的 liveness probe 状态发生了变化,则会产生事件。
- housekeepingCh: 该信息源也是一个周期性信号源(默认2秒),周期性的清理一些无用 pod。
所有的这些消息源产生的消息都由 kubelet 对象统一接受,并且调用相应的功能函数来完成相应的操作。
kubelet 对象自身实现一系列处理不同事件的 handler 函数,并且汇总成 SyncHandler 接口,其中包含针对不同信息源里不同消息类型的处理函数
|
|
当然,每一个处理函数背后可能都需要 kubelet 对象去调用背后多个内部子模块来共同完成,比如 HandlePodAddition 函数,处理 Pod 的创建,其中可能需要
- 调用 kubelet.podManager 子模块 AddPod 函数,注册该 pod 信息
- 调用 kubelet.podWorker 子模块为这个 Pod 创建单独的 worker goroutine 完成具体的操作
- 调用 kubelet.containerManager 子模块为这个 Pod 创建相应的 Pod Level Cgroup
- 调用 kubelet.volumeManager 子模块为这个 Pod 准备需要被 Mount 到容器中的文件系统
- 调用 kubelet.containerRuntime 子模块真正的创建 Pod 的实体
- ….
所以综上,整个 kubelet 的所有内部子模块就是通过这种生产者消费者模型协调工作,及时将 Pod 以用户期望的状态维护在它所在的机器上。
上面说到的只是 kubelet 中和 pod 管理相关的结构,kubelet 中还包括一些为了
- 维护物理机稳定性
- 同步更新物理机配置
等目的,周期性不间断工作的子模块,他们也是 kubelet 中非常重要的一部分。
所以这篇文章作为一个综述,是一系列文章的开端,我将通过一系列博文来解析 kubelet 的内部结构的细节,针对 kubelet 每一个比较重要的子模块,子功能进行单独的介绍。